
For 10 years now, the crawler I use for the technical SEO website audits I do at Search Engine People is what's nowadays called TechSEO360. A hidden gem; cost-effective, efficient (crawls any site of any size), forward looking (e.g.: had AJAX support before other such crawler tools did). I've written about this website crawler before but wanted to do a more comprehensive all-in-one post.
TechSEO360 Explained
TechSEO360 is a technical SEO crawler with highlights being:
- Native software for Windows and Mac.
- Can crawl very large websites out-of-the-box.
- Flexible crawler configuration for those who need it.
- Use built-in or custom reports for analyzing the collected website data (although I usually rely on exporting all data to Excel and using its powerful filters, pivoting, automatic formatting, etc.).
- Create image, video and hreflang XML sitemaps in addition to visual sitemaps.
How This Guide is Structured
This guide will cover all the most important SEO functionality found in this software.
- We will be using the demo website https://Crawler.TechSEO360.com in all our examples.
- All screenshots will be from the Windows version – but the Mac version contains the same features and tools.
- We will be using TechSEO360 in its free mode which is the state switched to when the initial fully functional free 30 trial ends.
- We will be using default settings for website crawl and analysis unless otherwise noted.
- We will start by showing how to configure the site crawl and then move on to technical SEO, reports and sitemaps.
Configuring and Starting The Crawl
Most sites will crawl fine when using the default settings. This means the only configuration required will typically be to enter the path of the website you wish to analyze - whether it is residing on the internet, local server or local disk.
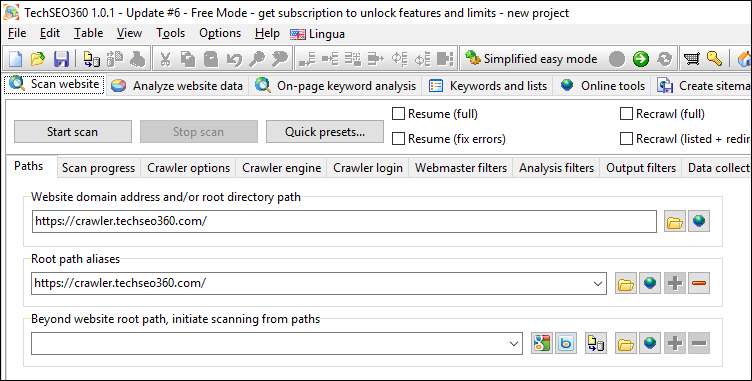
As an easy alternative to manual configuration, it is also possible to apply various "quick presets" which configures the underlying settings. Examples could be:
- You know you want to create a video sitemap and want to make sure you can generate the best possible.
- You use a specific website CMS which generate many thin content URLs which should be excluded.
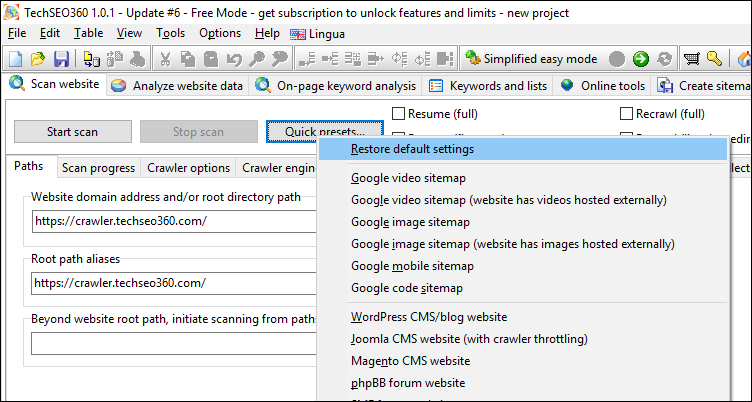
For those who want to dive into settings, you can assert a near-complete control of the crawl process including:
Crawler Engine
This is where you can mess around with the deeper internals of how HTTP requests are performed. One particular thing is how you can increase the crawling speed: Simply increase the count of simultaneous threads and simultaneous connections - just make sure your computer and website can handle the additional load.
Webmaster Filters
Control to what degree the crawler should obey noindex, nofollow, robots.txt and similar.
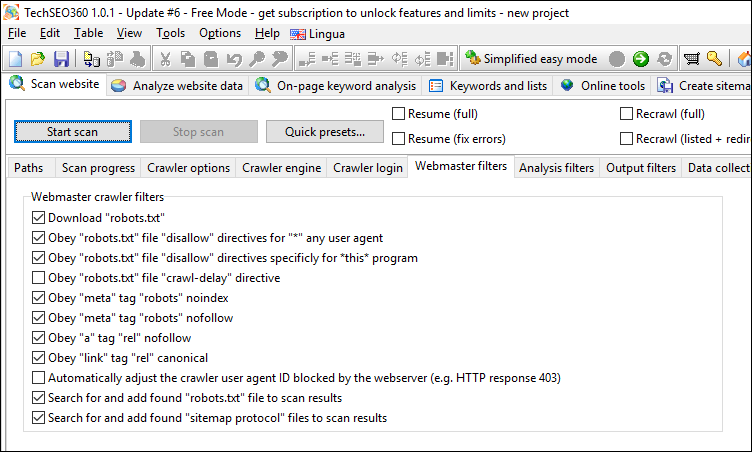
Analysis Filters
Configure rules for which URLs should have their content analyzed. There are multiple "exclude" and "limit-to" filtering options available including URL patterns, file extensions and MIME types.
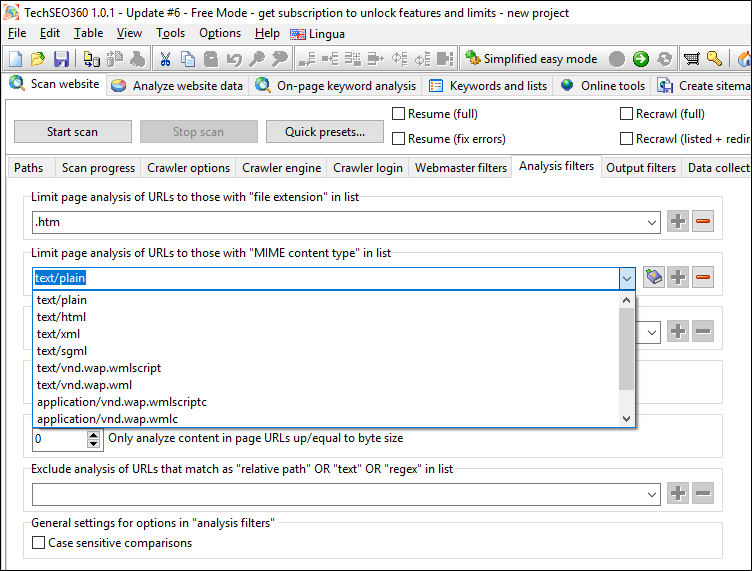
Output Filters
Similar to "Scan website | Analysis filters" - but is instead used to control which URLs get "tagged" for removal when a website crawl finishes.
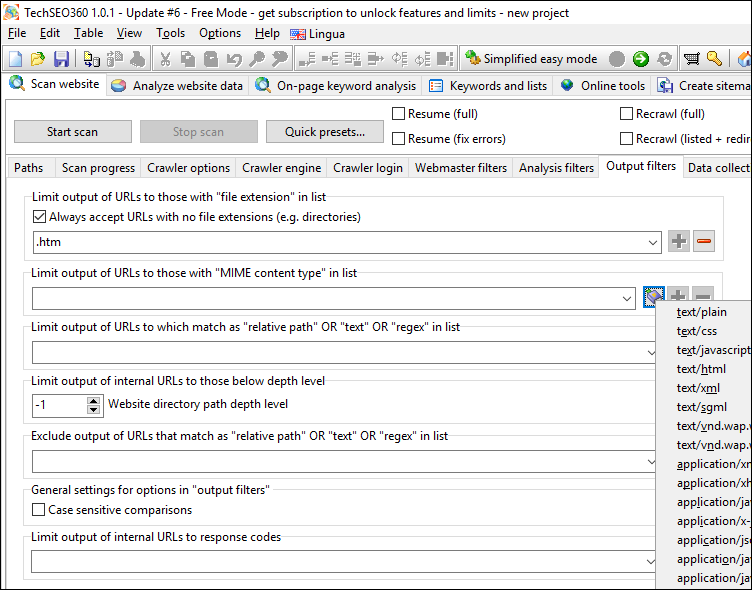
URLs excluded by options found in "Scan website | Webmaster filters" and "Scan website | Output filters" can still be kept and shown after the website crawl stops if the option "Scan website | Crawler options | Apply webmaster and output filters after website scan stops" is unchecked. With this combination you:
- Get to keep all the information collected by the crawler, so you can inspect everything.
- Still avoid the URLs being included when creating HTML and XML sitemaps.
- Still get proper "tagging" for when doing reports and exports.
Crawl Progress
During the website crawl, you can see various statistics that show how many URLs have had their content analyzed, how many have had their links and references resolved and how many URLs are still waiting in queues.
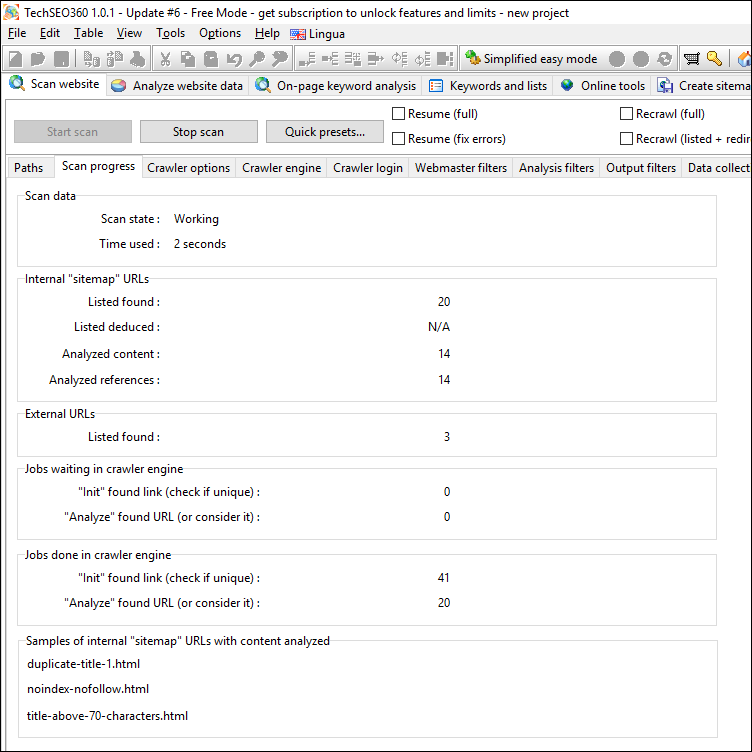
Website Overview After Crawl
After a site crawl has finished the program opens up a view with data columns to the left:
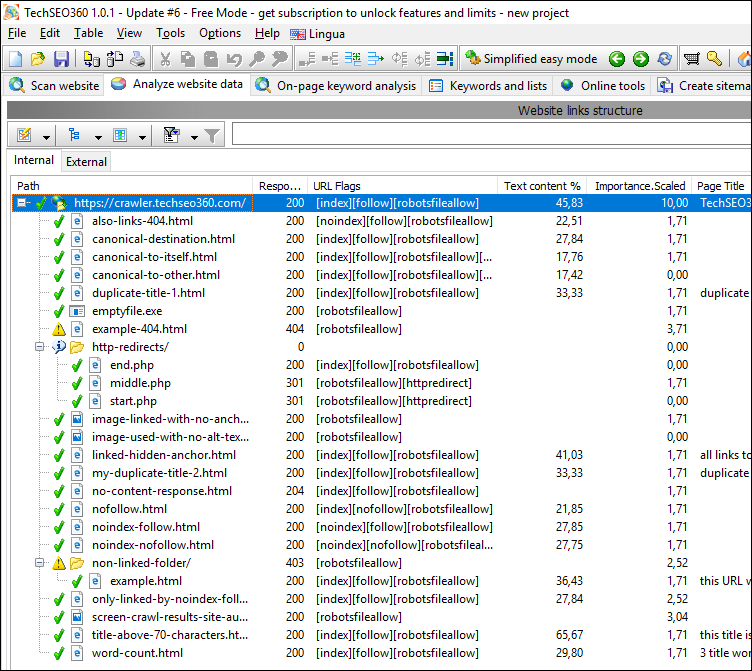
If you select an URL you can view further details to the right:
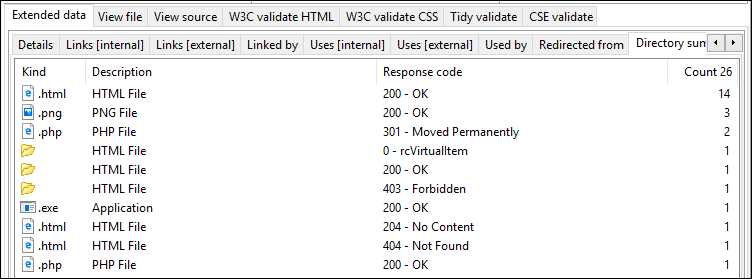
Here is a thumbnail of how it can look on a full-sized screen:
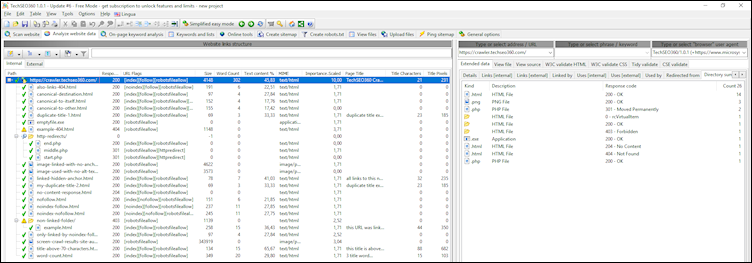
Left Side
Here you will find URLs and associated data found during the website scan. By default only a few of the most important data columns are shown. Above this there is a panel consisting of five buttons and a text box. Their purposes are:
#1
Dropdown with predefined "quick reports". These can be used to quickly configure:
- Which data columns are visible.
- Which "quick filter options" are enabled.
- The active "quick filter text" to further limit what gets shown.
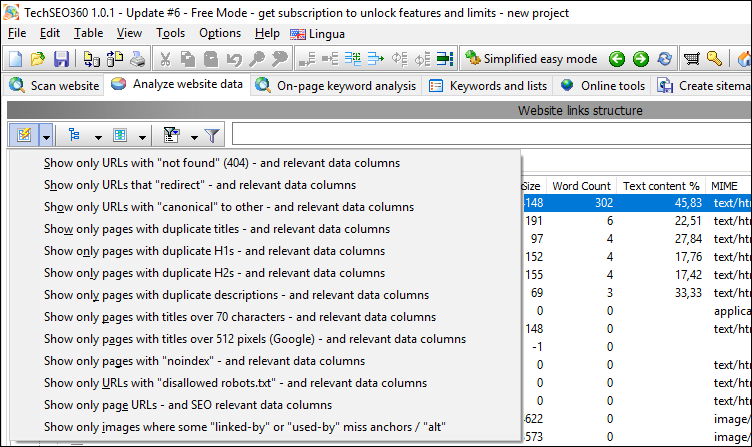
#2
Dropdown to switch between showing all URLs in the website as a flat "list" versus as a "tree".
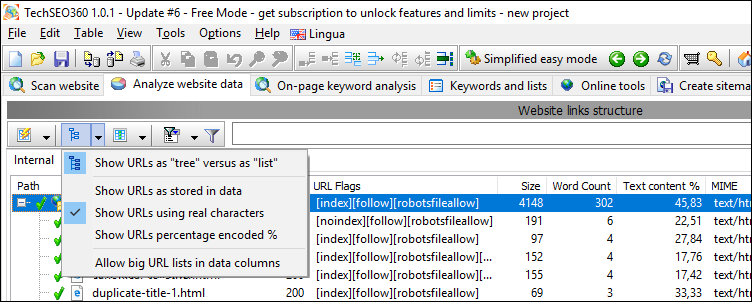
#3
Dropdown to configure which data columns are visible.
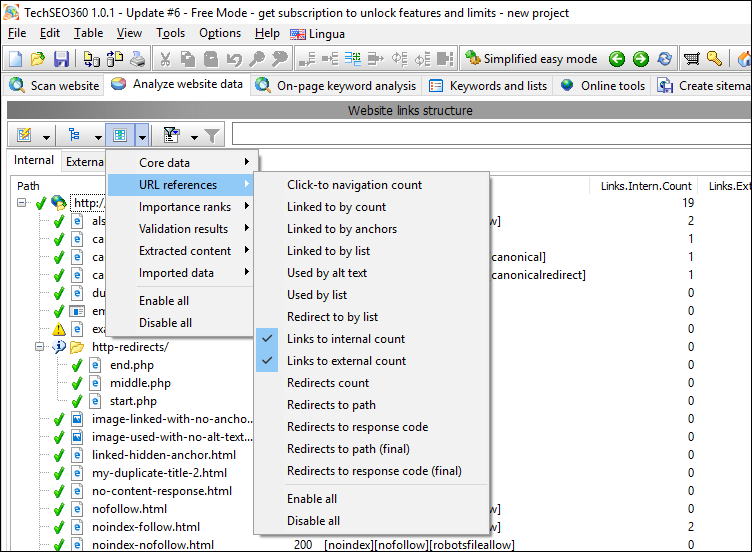
#4
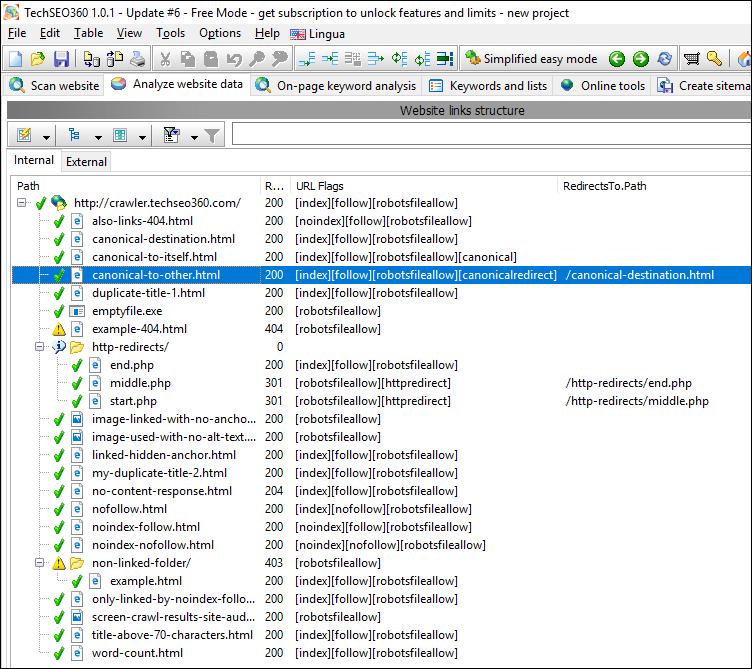
Compared to the above, enabling visibility of data column "Redirects to path" looks like this:
#5
Dropdown to configure which "quick filter options" are selected.
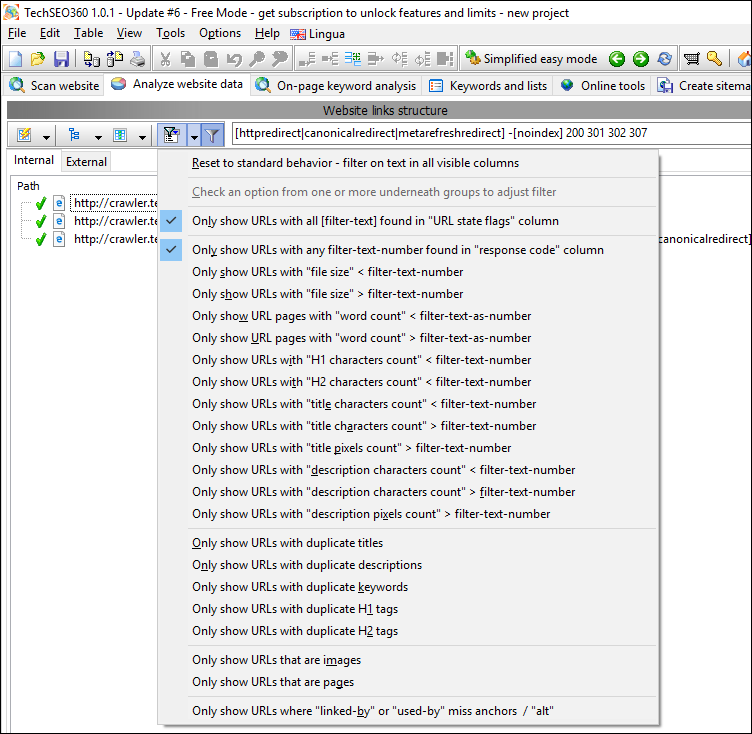
#6
On/off button to activate/deactivate all the "quick filters" functionality.
#7
Box containing the "quick filter text" which is used to further customize what gets shown.
How to use "quick reports" and "quick filters" functionality will be explained later with examples.
Right Side
This is where you can see additional details of the selected URL at the left side. This includes "Linked by" list with additional details, "Links [internal]" list, "Used by" list, "Directory summary" and more.
To understand how to use this when investigating details compare the following two scenarios.
#1
At the left we have selected URL https://crawler.techseo360.com/noindex-follow.html - we can also see the crawler has tagged it "[noindex][follow]" in the data column "URL flags":
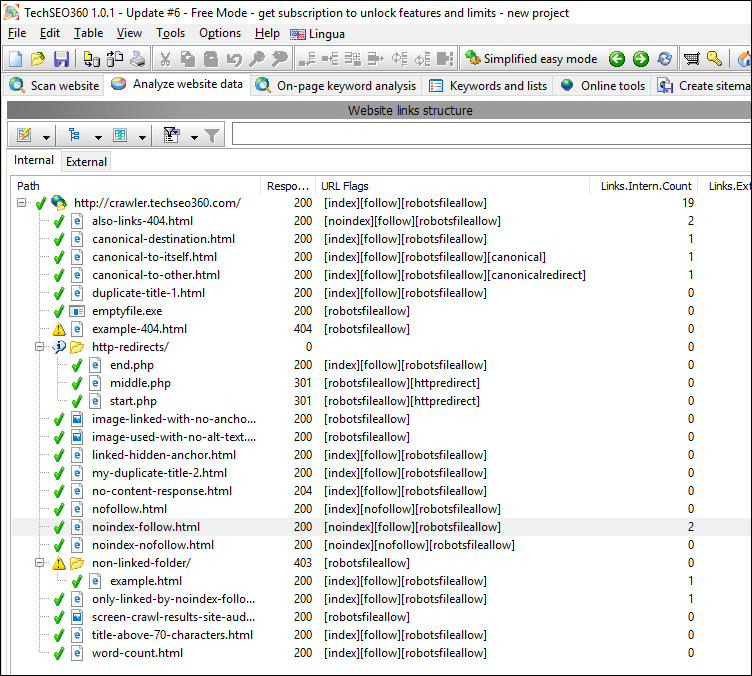
To the right inside the tab "Links [internal]", we can confirm that all links have been followed including and view additional details.

#2
At the left we have selected URL https://crawler.techseo360.com/nofollow.html - we can also see the crawler has tagged it "[index][nofollow]" in the data column "URL flags".:
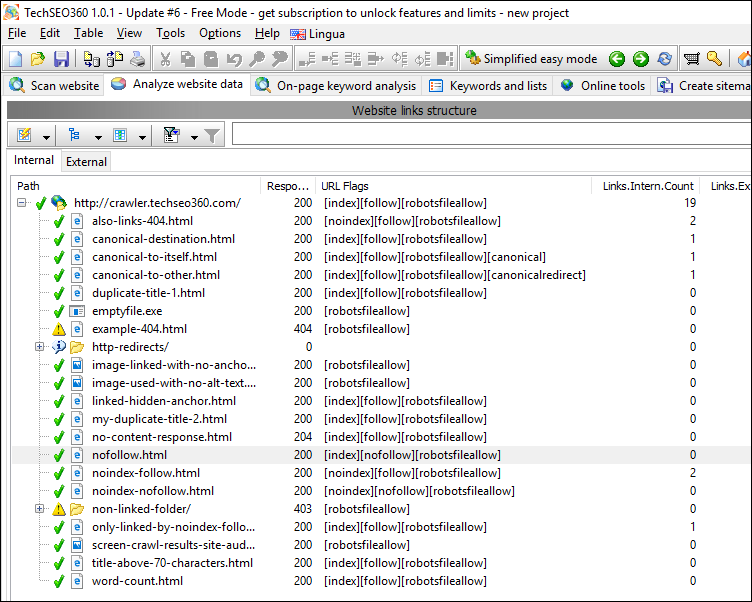
To the right inside the tab "Links [internal]", we can confirm that no links have been followed.

Using Quick Reports
As I said, I don't often use these, preferring to Show All Data Columns, and then export to Excel. But for those who like these kind of baked-in reports in other tools, here are some of the most used quick reports available:
All Types of Redirects
The built-in "quick report" to show all kinds of redirects including the information necessary to follow redirect chains:
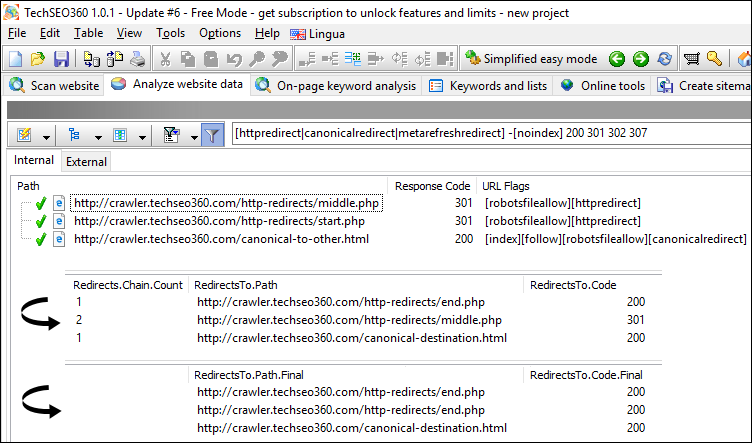
Essentially this has:
- Changed the visibility of data columns to those most appropriate.
- Set the filter text to:
[httpredirect|canonicalredirect|metarefreshredirect] -[noindex] 200 301 302 307 - Activated filters:
Only show URLs with all [filter-text] found in "URL state flags" columnOnly show URLs with any filter-text-number found in "response code" column
With this an URL has to fulfil the following three conditions to be shown:
- Has to point to another URL by either HTTP redirect, canonical instruction or "0 second" meta refresh.
- Can not contain a "noindex" instruction.
- Has to have either response code 200, 301, 302 or 307.
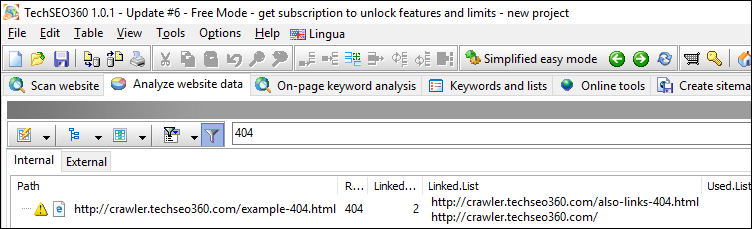
404 Not Found
If you need to quickly identify broken links and URL references, this report is a good choice. With this, the data columns "Linked.List" (e.g. "a" tag), "Used.List" (e.g. "src" attribute) and "Redirected.List" are made visible.
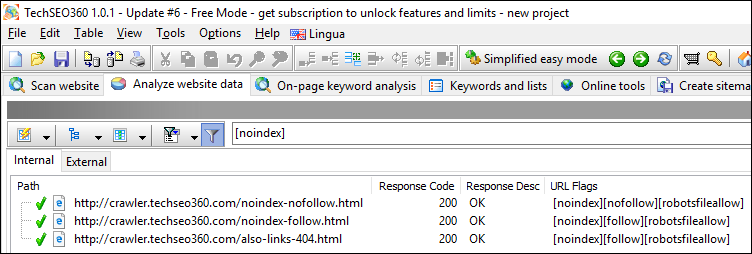
Noindex
Quickly see all pages with the "noindex" instruction.
Duplicate Titles #1
Quickly see all pages with duplicate titles including those with duplicate empty titles.
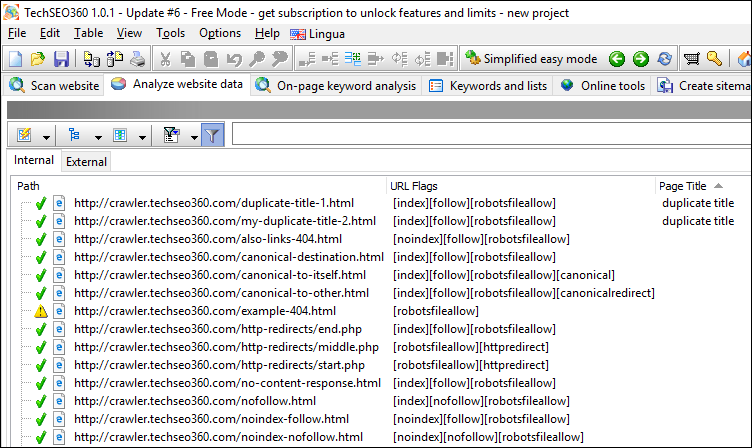
Duplicate Titles #2
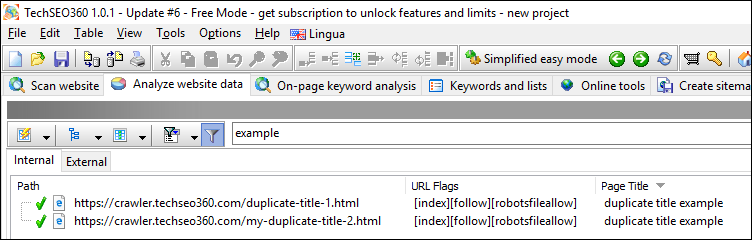
If not overridden by other filters, filter text matches against content inside all visible data columns. Here we have narrowed down our duplicate titles report to those that contain the word "example".
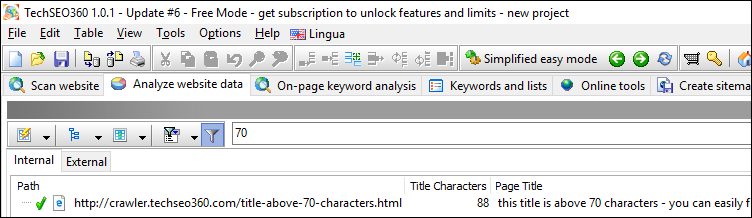
Title Characters Count
Limit the URLs shown by title characters count. You can control the threshold and if above or below. Similar is available for descriptions.
Title Pixels Count
Limit the URLs shown by title pixels count. You can control the threshold and if above or below. Similar is available for descriptions.
![]()
Images and Missing Alt / Anchor Text
Only show image URLs that was either used without any alternative text or linked without any anchor text.
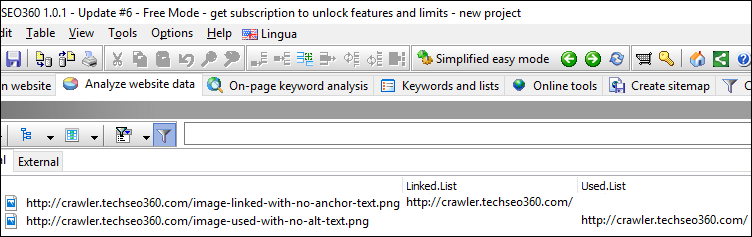
Other Tools
On-page Analysis
By default there is performed comprehensive text analysis on all pages during the website crawl. The option found for this resides in "Scan website | Data collection" which gives results like these:
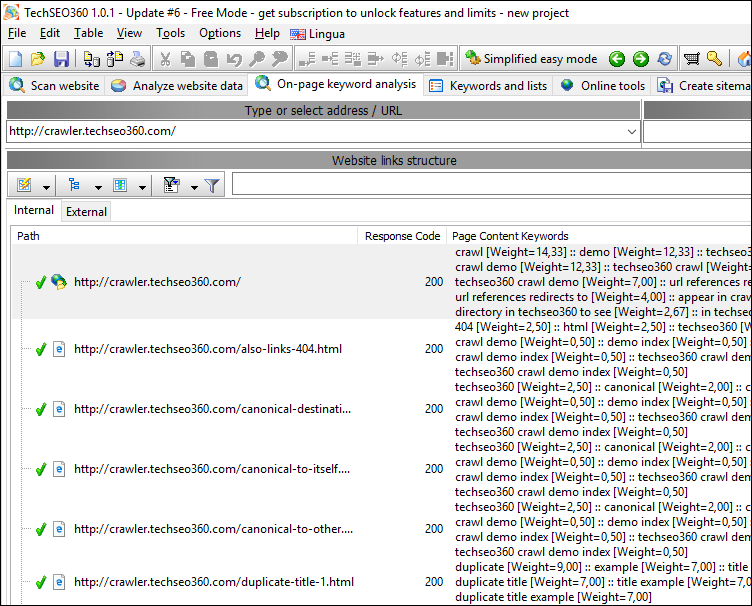
However, you can also always analyze single pages without crawling the entire website:
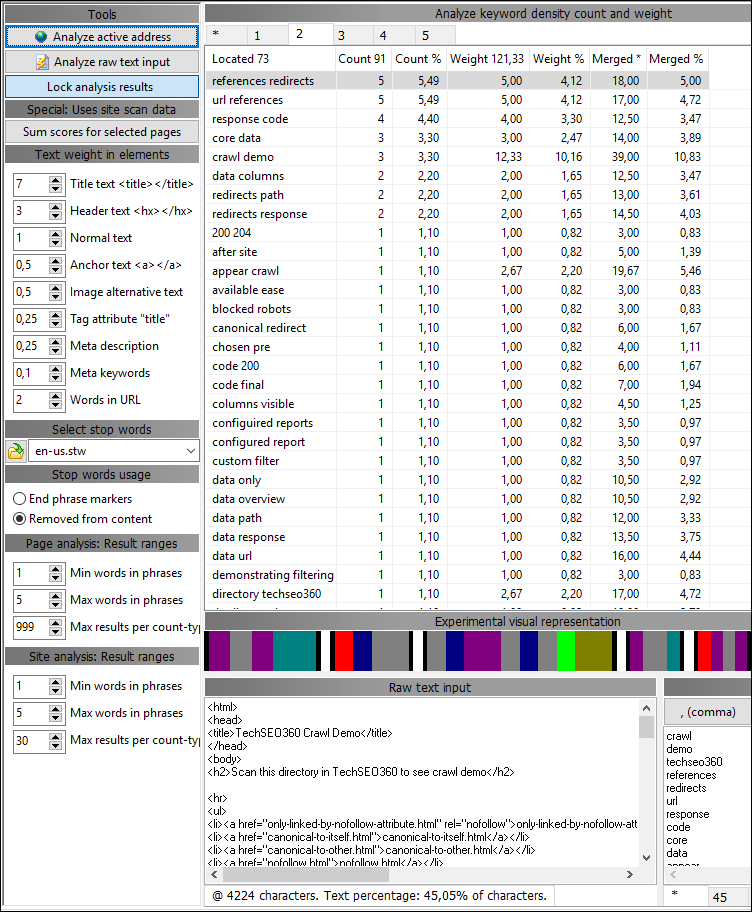
Notice that you can see which keywords and phrases are targeted across an entire website if you use the "sum scores for selected pages" button.
Keyword Lists
A flexible keyword list builder that allows to combine keyword lists and perform comprehensive clean-up.
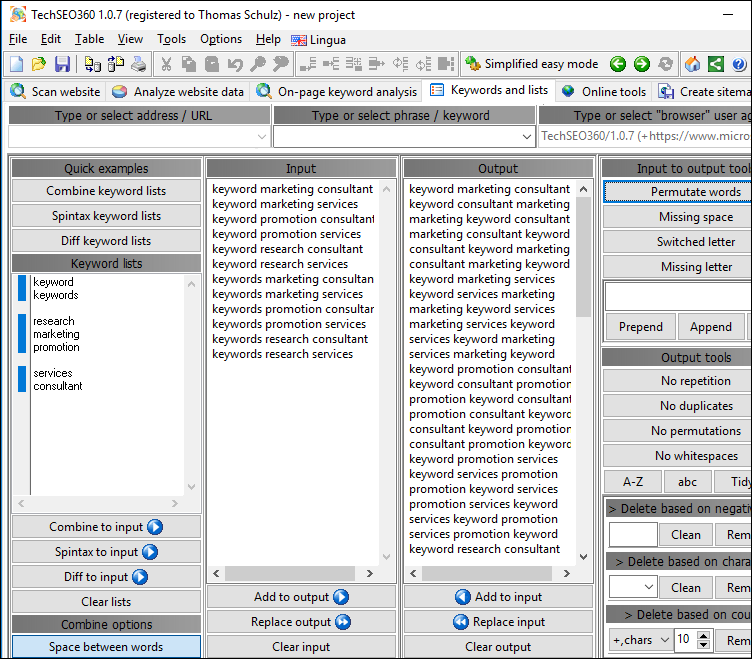
3rd Party Online Tools
If you need more tools, you can add them yourself and even decide which should be accessible by tabs instead of just the drop-down.
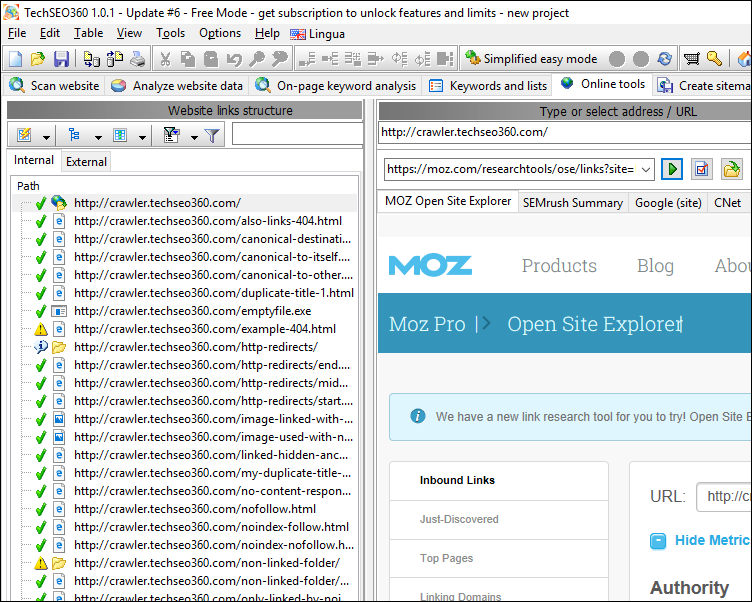
The software will automatically pass on the selected URL or similar to the selected online tool. Each online tool is configured by a text file that defines which data is passed and how it is done.
Sitemaps
Sitemap File Types
With 13 distinct sitemap file formats, chances are your needs are covered. This includes XML sitemaps, video sitemaps and image sitemaps.
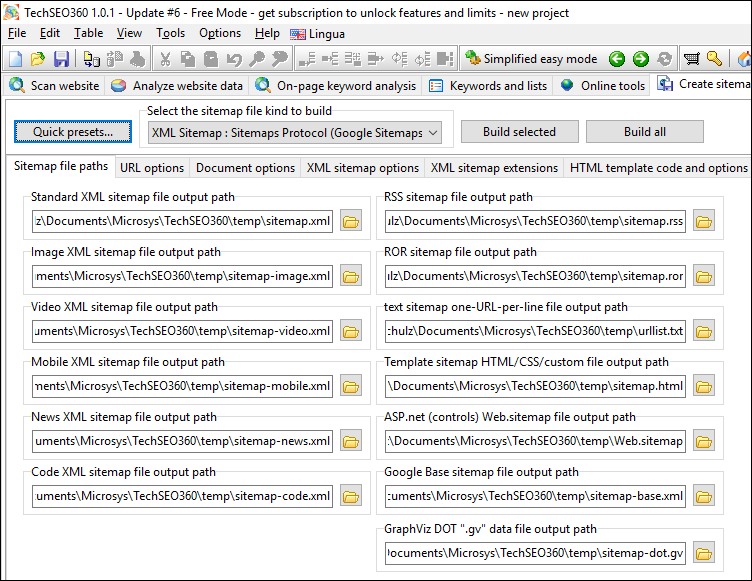
XML Sitemaps and Hreflang
Even if your website does not include any hreflang markup, TechSEO360 will often be able to generate XML sitemaps with appropriate alternate hreflang information if your URLs contain parts that includes a reference to the language-culture or country.
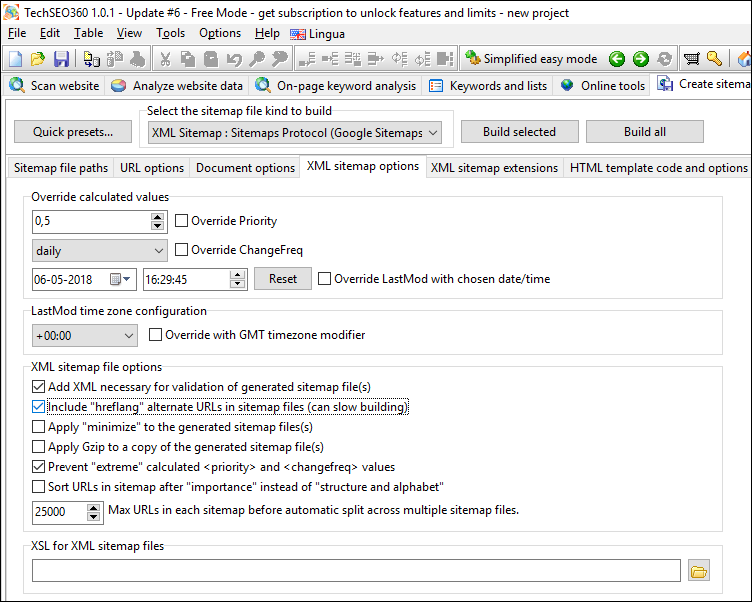
XML Image and Video Sitemaps
You can usually speed-up your configuration by using one of the "Quick presets":
- Google video sitemap
- Google video sitemap (website has videos hosted externally)
- Google image sitemap
- Google image sitemap (website has images hosted externally)
If you intend to create both image and video sitemaps, use one of the video choices since they also include all the configuration optimal for image sitemaps.
TechSEO360 uses different methods to calculate which pages, videos and images belong together in generated XML sitemaps - something that can be tricky if an image or video is used multiple places.
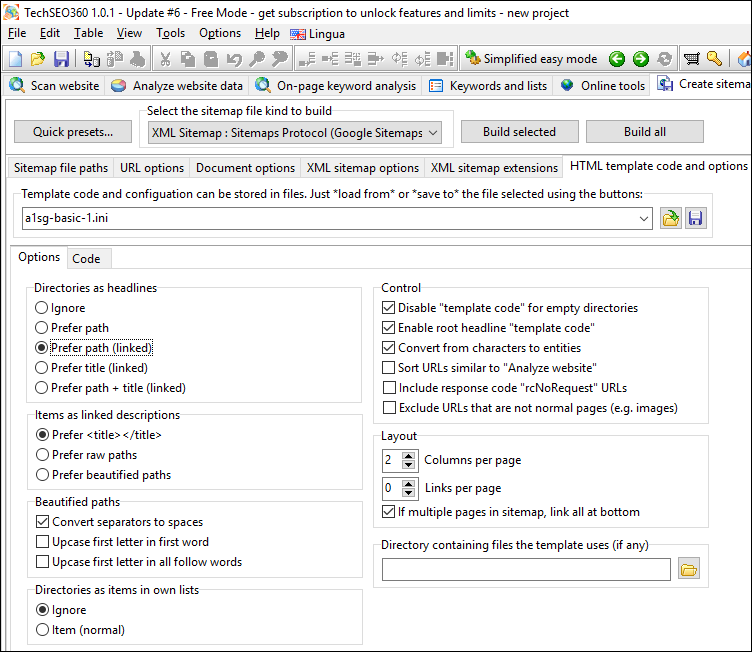
HTML Sitemaps
Select from the built in HTML templates or design your own including the actual HTML/CSS/JS code and various options used when building the sitemaps.
Other Functionality
Javascript and AJAX Support
You can configure TechSEO360 to search Javascript code for file and URL references by checking the option "Scan website | Crawler options | Try search inside Javascript".
If you are dealing with an AJAX website you can switch to an AJAX enabled solution in "Scan website | Crawler engine | Default path type and handler".
Custom Text and Code Search
It can often be useful to search for text and code across an entire website - e.g. to find pages using old Google Analytics code or similar.
You can configure multiple searches in "Scan website | Data Collection" | Search custom strings, code and text patterns".
The results are shown in the data column "Page custom searches" showing a count for each search - optionally with the content extracted from the pattern matching.
Calculated Importance Score
TechSEO360 calculates importance of all pages based on internal linking and internal redirects.
You can see this by enabling visibility of the data column "Importance score scaled".
Similar Content Detection
Sometimes pages are similar but not exact duplicates. To find these, you can enable option "Scan website | Data Collection | Tracking and storage of extended data | Perform keyword analysis for all pages" before scan.
When viewing results enable visibility of the data column "Page content duplicates (visual view)" and you will get a graphical representation of the content.
Command Line Interface (CLI)
If you are using the trial or paid version, you can use the command line - here is an example:
"techseo.exe" -exit -scan -build ":my-project.ini" @override_rootpath=https://example.com@
The above passes a project file with all options defined, overrides the website domain and instructs TechSEO360 to run a complete crawl, build of sitemaps and exit.
Importing Data
The "File | Import..." functionality works intelligently and can be used to:
- Import URLs lists. If the URLs imported are from mixed domains, TechSEO360 will determine if there is a primary domain and import appropriately into the "Internal" and "External" tabs.
- TechSEO360 can also detect various other data sources which content instead will be added to the existing data:
- Apache server logs to "tag" URLs visited by GoogleBot "[googlebot]" and detect URLs not internally linked/used "[orphan]".
- Google Webmaster Tools exports to "tag" URLs indexed by Google "[googleindexed]" and data for clicks and impressions.
- Majestic CSV exports for backlinks score data.
The above "[...]" can be used by the "quick filters text" to generate further customized reports.
Exporting Data
The "File | Export..." functionality can export data to CSV, Excel, HTML and more depending on what you are exporting. To use:
- Select the control with the data you wish to export.
- Apply options so the control only contains the data you wish to export. (This can e.g. include "data columns", "quick filter options" and "quick filter text")
- Click the "Export" button and you now have the data you want in the format you want.
TechSEO360 Pricing
There are essentially three different states:
- When you first download the software you get a fully functional 30 days free trial.
- When the trial expires it still continues to work in free mode which allows to crawl 500 pages in websites.
- When purchasing the yearly subscription price is $99 for a single user license which can be used on both Windows and Mac.
You can download the trial for Windows and Mac at https://TechSEO360.com.



